As a new fintech startup, one of our best ways to grow is making our product fit what high-value partners need. When a major partner came to us with a special request for their embedded capital program, we faced a tough technical challenge. This blog post illustrates how we navigated the art of configurability to make our product flexible enough for an enterprise partner while keeping our technical standards and loan approval process strong.
Our partner wanted to show "pre-approved offers" to their merchants without releasing any merchant data to our systems. This created a problem with our typical underwriting process, which usually works by processing merchant sales data sent to our servers. Pre-approved offers are a key part of our strategy—they boost conversion rates and reduce adverse selection by reaching a broader, more representative set of borrowers—so finding a way to deliver them despite this constraint was critical.
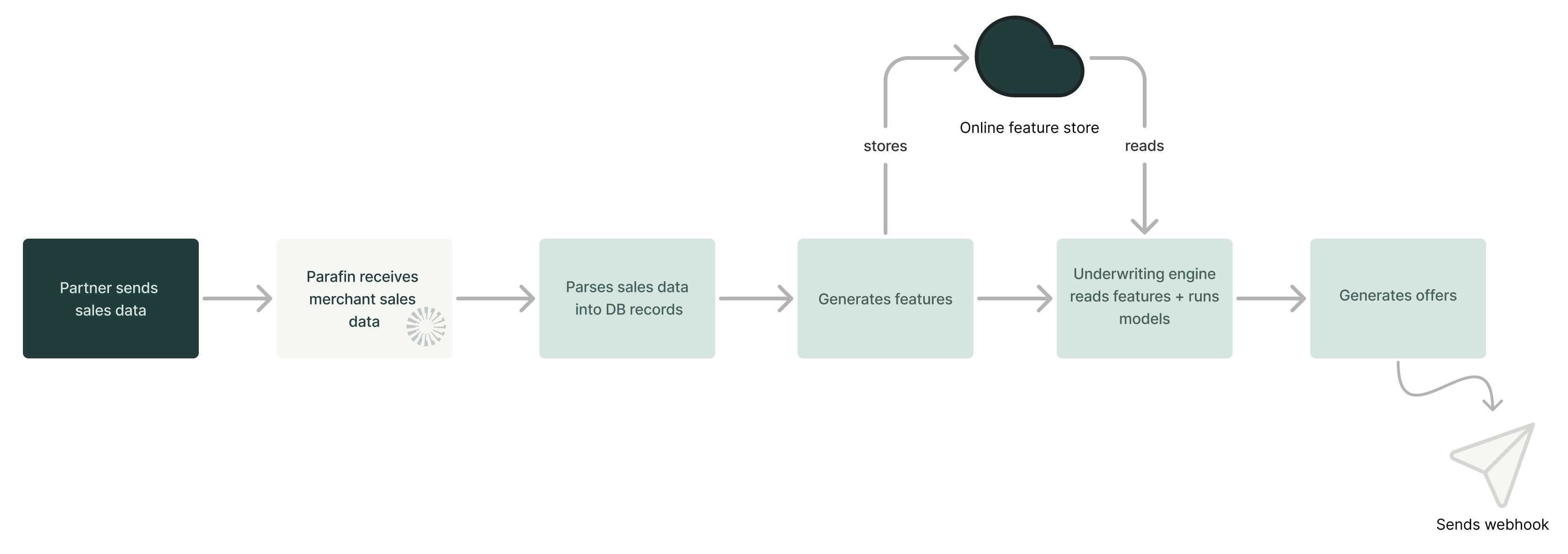
Our standard underwriting system works by:
1. Analyzing daily sales data shared by partners
2. Computing risk scores via machine learning models hosted on MLFlow
3. Predicting future sales
4. Extracting features that provide a condensed view of business health
5. Running Python modules that determine eligibility, loan amounts, and pricing
6. Sharing pre-approval offers back with partner
The ask from our potential partner essentially meant: "We want to show merchants how much your underwriter would lend them, but we don't want our data going through your underwriter." This presented a fundamental challenge to our operational model.
In the lending business, precision isn't just a nice-to-have—it's essential for survival. A single miscalculated offer can wipe out the lending profits from 30 good offers. Mistakes are incredibly costly, and we've built our systems to require a comprehensive view of a business before extending credit offers. Worse, an offer that puts undue repayment burden on a business can put them into a debt spiral.
We initially found ourselves at a deadlock. How could we provide accurate offers without the very tool designed to generate those offers? The simple answer was: we couldn't.
Returning to the fundamentals, we recognized that we couldn't underwrite merchants without their data. However, we could design a system where merchants could opt-in to share their data with us through the partner. Once they granted permission, we could underwrite and extend offers through our normal process. Note: this would still not be a true pre-approval as merchants would have to take some explicit action before they see a pre-approved offer value.
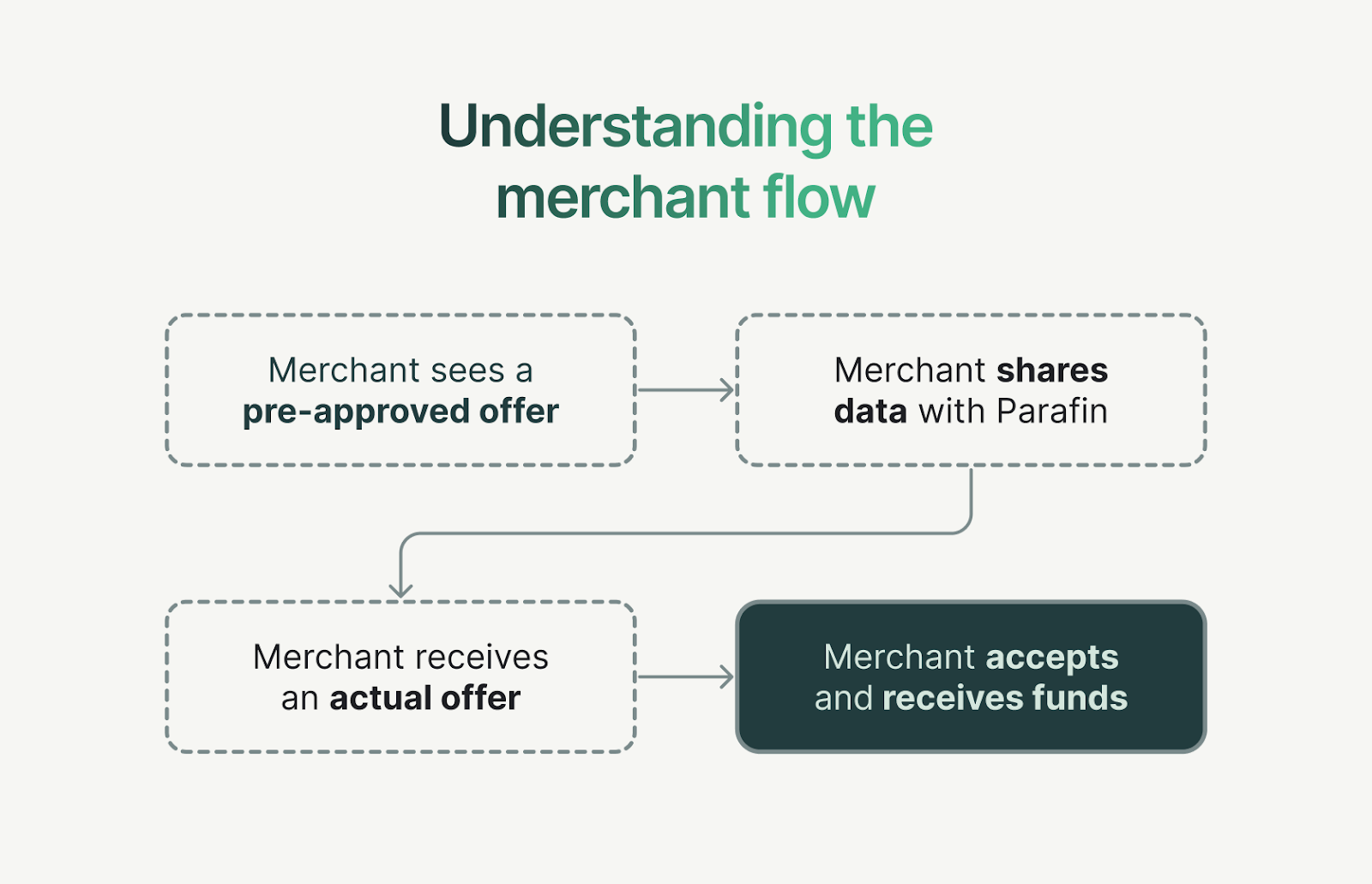
Our next question was: why not just display a generic message like "Sign up for our capital program! You could be eligible for up to XXX dollars!"? Well, this approach violated our product value around transparency. It would create a bad experience for merchants if they signed up only to get a much smaller offer or be denied.
We needed to solve a more complex problem: show merchants an offer estimate that would interest them enough to apply, while making sure the estimate would be very close to the actual offer they'd get after full review.
This brought us back to the main theme of configurability: How could we adjust our loan approval system to handle this special request?
For the first time, our underwriter itself became the product we were launching.
If partner data could never leave their machines, then our underwriting system needed to run locally on their infrastructure. This sounds straightforward until you consider the complexity of our underwriting process.
Our standard process involves:
The challenge was to package our loan approval system, including all risk models, forecasting tools, and eligibility rules, into a self-contained program that the partner could install and use like a plug-and-play toolkit. We experimented with hosting APIs and using clean rooms (secure data environments where code runs without direct data access), but neither approach fully met our needs. That left us with tough questions: How would we generate and store features on the fly? How would we access our online feature store?
We needed a solution for locally storing and querying features. After looking at several options, we chose DuckDB because it can create temporary databases that exist only while the program runs. These can be used like regular databases but don't need separate database systems. These tables could be queried as if they were persisted in a traditional SQL database but without requiring external database infrastructure or any kind of configuration on the partner’s end. Our internal feature pipeline is mostly SparkSQL-based, so converting everything to Python or trying to run Spark on their system would have been a major headache—DuckDB let us sidestep that complexity.
However, we faced another challenge: memory management. The partner had approximately 105,000 merchants they wanted to evaluate through our local underwriter. Processing this volume of data simultaneously would cause out-of-memory errors on standard machines. We needed to build our packaged underwriter to support the maximum number of businesses without crashing.
Our solution was to batch the businesses and clear in-memory tables between each batch. This approach traded computation time for reduced memory requirements. Since new offers would only be created once every two weeks, the increased processing time was an acceptable tradeoff. We started with intentionally low system requirements on the partner’s side—for example, avoiding use of the filesystem to sidestep any issues with limited permissions or access—and prioritized low memory usage, even if it meant higher latency. This made it possible for the partner to run the system with minimal configuration.
For features that would typically be retrieved from our online feature store, we decided to recompute those values in memory. Our feature values are computed by making calls to MLflow models that we host. To replicate this functionality, we packaged JSON versions of those models with our SDK. The local system would then use the MLflow SDK to reconstruct these into XGBoost models and generate risk scores within the same process.
This approach worked well, though it introduced a new consideration: version management. Our underwriting models are constantly improving—through better feature engineering, retraining, and tuning—and these upgrades are a critical part of delivering accurate and competitive offers. But with each improvement came the need to generate and distribute a new version of the SDK. To streamline this, we developed an internal pipeline that automatically packaged and versioned each model update into a new SDK, which we could then send to the partner. Thanks to the simplicity of their integration with our underwriter, these updates remained low-friction, typically taking only a few minutes for both teams to deploy. This allowed us to continue shipping model improvements at our usual pace without disrupting their merchant experience.

This project reinforced that configurability isn't a science but rather an art. It requires careful thinking about how to customize your products to meet customer needs while maintaining consistency and technical quality.
The key questions we continually asked ourselves were:
Creating a self-contained underwriting package that could run inside the partner’s systems wasn’t just a workaround—it was a new way to meet strict data privacy needs. It let us bring on a major partner without sacrificing model quality or the merchant experience: pre-approved offers stayed accurate and seamless, while data stayed protected. More broadly, it was a step toward building flexible systems that can support the growing privacy expectations of large enterprises. As data privacy becomes more important, we’re planning ahead—making sure we can meet future needs while still delivering strong performance and earning merchant trust.
Integrating with our partner’s platform taught us important lessons about balancing configurability with standardization. By thinking creatively and going back to basics, we found a solution that worked for our partner without lowering our loan approval standards.
In fintech partnerships, sometimes the best solutions don't come from new technologies, but from using existing ones in new ways. Building a packaged loan approval system specifically for a prospective partner was exactly this kind of innovation—a special version of our core technology that helped us win a big partnership while maintaining the quality of our loan approval process.



